实验室在《Analytica Chimica Acta》发表非靶向代谢组学数据分析方法领域的研究成果

西南特色中药资源国家重点实验室胡凯锋团队在非靶向代谢组学数据分析方法研究中取得进展。相关成果以“Comparing univariate filtration preceding and succeeding PLS-DA analysis on the differential variables/metabolites identified from untargeted LC-MS metabolomics data”为题,于2024年1月25日在线发表于《Analytica Chimica Acta》杂志。西南特色中药资源国家重点实验室为第一通讯作者单位,中医药创新研究院/交叉学科研究院胡凯锋教授为通讯作者,基础医学院2020级博士研究生许愫芸和基础医学院博士后柏彩红为本文共同第一作者。
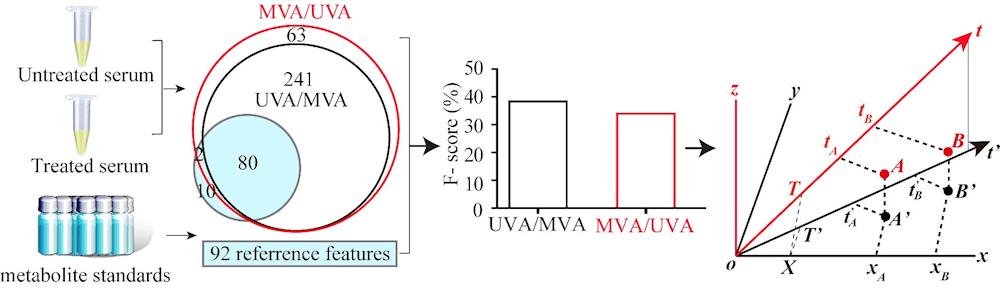
在非靶向代谢组学研究中,单变量分析和多变量分析通常被整合使用,旨在筛选高维数据中与样本分类有显著意义的差异变量(特征或代谢物),从而揭示生物标志物、疾病发病机理和药物作用机制。偏最小二乘判别分析是非靶向代谢组学研究中常用的多变量分析方法之一。然而,对于同一组非靶向代谢组学LC-MS数据,在PLS-DA之前进行单变量分析或在PLS-DA之后进行单变量分析(MVA/UVA)可能会产生不同的代谢组学结果。该研究使用血清数据集和线虫数据集探究了UVA/MVA和MVA/UVA两种不同的数据分析方案产生不一致的差异变量的原因。
该研究发现,LC-MS数据中存在大量无关变量的波动和正交噪声可能会扭曲PLS-DA构建的模型,影响p(corr)值,并由于模型构建中输入变量的总数增加,使得计算出的相关特征的VIP通常偏大。研究结果表明,针对非靶向代谢组学LC-MS数据,在PLS-DA之前进行单变量数据预过滤,通常会得到数目更少但更稳健可靠的差异特征。而直接PLS-DA分析包含大量噪音或测量波动的LC-MS数据,可能会产生扭曲的PLS-DA模型,并造成相关变量的VIP值膨大。导致采样常用的VIP最小阈值(1.0)筛选差异变量将产生更多的假阳性结果。因此,如果PLS-DA之前未经单变量预过滤,建议提高筛选差异变量的VIP阈值,有助于降低假阳性率。
该研究获得国家自然科学基金(22374012, 32171440)和四川省自然科学基金(2022NSFSC0719)支持。
全文链接:https://doi.org/10.1016/j.aca.2023.342103